Linux Distributions Running On Intel CPUs Are About To Get A Lot Slower
GNU/Linux distributions have very quietly begun rolling out a microcode update for Intel CPUs which contain "Mitigations for Jump Conditional Code Erratum". Errata is a fancy way of saying defective due to a design flaw. Intel consumer CPUs from 6th generation Skylake up to the latest 10th generation "Come Lake" CPUs as well as Xeon CPUs released in that time-frame have a design flaw which can cause "unpredictable" behavior under certain conditions. The new microcode which works around this design flaw has a 2-20% performance penalty. This comes on top of new performance-hampering security-mitigations for other Intel CPU design flaws which were added to the stable kernel branches this week.
"Unpredictable Behavior"[edit]
Intel CPUs have been caching decoded instructions in what they call a ICache since the now very old Sandy Bridge CPU architecture. Re-using decoded instructions instead of decoding them again and again provides a very real performance-benefit and it is generally a good idea. Apparently, something went very wrong and every Intel CPU from Skylake onward can behave "unpredictably" when this ICache is used for jump instructions. Exactly what Intel means by "unpredictable behavior" is unclear. There are no widespread reports of software running on Intel CPUs crashing ten times per day or other well-known issues. Keep in mind that this flaw has been in most Intel CPUs for years now.
The older Intel CPU architectures Haswell and Broadwell, from 2014 and 2015 respectively, do not have the conditional jump design flaw. Most Intel CPU architectures after that can run into issues if a decoded jump instruction which happens to cross a 32-byte boundary is cached and re-used. Low-power CPU architectures like Goldmount and Silvermount are not affected.
The instructions that are problematic on affected Intel CPUs are:
- Conditional jump.
- Fused conditional jump.
- Unconditional jump.
- Call.
- Ret.
- Indirect jump and call.
The Performance Penalty[edit]

Intel has published a "whitepaper" created on November 11th in Microsoft Word for Office 365 called "Mitigations for Jump Conditional Code Erratum" which not really describes the design flaw and it's implications. The whitepaper claims that the newly released microcode will have a 0-4% performance-penalty depending on workload. Numbers published by OpenBenchmarking indicate that the real-world performance-impact is in the 2-20% range. Most workloads suffer a 3-5% performance loss while some corner-cases have a 20% performance hit.
Intel's whitepaper notes that some of the performance lost by applying their latest CPU microcode update can be clawed back by re-compiling programs with compiler switches which "optimize" code to run faster on defectively designed Intel CPUs with microcode workarounds. A series of patches with code for a new -mbranches-within-32B-boundaries compiler option which "aligns conditional jump, fused conditional jump and unconditional jump within 32-byte boundary" has been proposed on the binutils mailing list.
A slight problem with Intel's proposed "optimizations" is that their supposed solution does not optimize the resulting assembler code. The flaw in Intel CPUs make the affected CPUs behave unpredictably, whatever that means, if a decoded cached jump instruction crosses a 32-byte boundary or ends in a 32-byte boundary. The new firmware update ensures that instructions are not cached in those cases. Intel proposes that developers "optimize" code so jump instructions do not cross or end in a 32-byte boundary. This can be done by padding instructions with prefixes. It does work and it may provide a performance benefit to the affected defective-by-design Intel CPUs. However, low-power Intel CPUs like Goldmount and Silvermount as well as AMD CPUs will have to do more work to run a "Intel Optimized" binary compiled with flags that align jump instructions in this fashion.
It will be interesting to see if the various GNU/Linux distributions decide to implement Intel's "optimizations" or not. Here we have a giant chip-maker asking everyone to re-compiles everything so the performance penalty of a design flaw workaround in their products appear to be smaller while adding a performance penalty to their competitors non-flawed correctly-functioning chips. That's a rather bold demand. Concretely, Intel wants a -mbranches-within-32B-boundaries compiler flag and they want it to be used everywhere.
RedHat asset and Binutils developer Jeff Law had this to say about Intel's "optimization" proposals:
"I can't help but point out that if we do this, then we're forcing everyone to pay a price in terms of runtime performance and codesize -- even if they're on a processor where this doesn't matter.
Additionally, I have yet to find any documentation which indicates with better precision when this happens and what the consequences are when it does happen. That makes it impossible to know if there's any kind of filtering we can do to avoid inserting to many nops/prefixes to ensure branch alignment. It's also exceedingly hard to assess the real world impact of the bug which in turn makes it hard to assess the importance of the mitigations."
in a message titled "Re: PATCH 0/5 i386: Optimize for Jump Conditional Code Erratum"
on November 14th.
Your Firmware Will Be Updated[edit]
The Intel CPU firmware is located in the /lib/firmware/intel-ucode/ folder on the vast majority of GNU/Linux distributions. It is provided by a package named something like microcode_ctl (Fedora 31). Linux distributions are in the processes of shipping updated packages which replace the files in that folder with new performance-hampering flaw-fixing microcode. You will be getting the microcode updates if you are using GNU/Linux and you update your system using your distributions method regularly.
It Gets Worse[edit]
The long-term support branches of the Linux kernel got an update on November 12th which contain a small pile of new security mitigation code as well as new fixes and workarounds for Intel CPUs. Kernels 5.3.11, 4.19.84 and 4.14.154 and newer have these new security fixes. These are fixes for other issues that are unrelated to jump instruction caching.
A newly discovered Intel "ITLB_MULTIHIT bug" is described in the kernel changelog for 5.3.11 as:
"Some processors may incur a machine check error possibly resulting in an unrecoverable CPU lockup when an instruction fetch encounters a TLB multi-hit in the instruction TLB. This can occur when the page size is changed along with either the physical address or cache type. "
ITLB_MULTIHIT is specially worrysome for those running virtual machines. A kvm-specific patch addressing ITLB_MULTIHIT elaborates:
"With some Intel processors, putting the same virtual address in the TLB as both a 4 KiB and 2 MiB page can confuse the instruction fetch unit and cause the processor to issue a machine check resulting in a CPU lockup.
Unfortunately when EPT page tables use huge pages, it is possible for a malicious guest to cause this situation."
ITLB_MULTIHIT is not the only Intel-specific problem addressed in the latest stable-series kernels. There is also a performance-hampering fix for "TAA - TSX Asynchronous Abort". The kernel hardware guide recently got a chapter on TAA - TSX Asynchronous Abort which describes it as:
"TAA is a hardware vulnerability that allows unprivileged speculative access to data which is available in various CPU internal buffers by using asynchronous aborts within an Intel TSX transactional region."
The changelog for kernel 5.3.11 elaborates:
"TSX Async Abort (TAA) is a side channel vulnerability to the internal buffers in some Intel processors similar to Microachitectural Data Sampling (MDS). In this case, certain loads may speculatively pass invalid data to dependent operations when an asynchronous abort condition is pending in a TSX transaction.
This includes loads with no fault or assist condition. Such loads may speculatively expose stale data from the uarch data structures as in MDS. Scope of exposure is within the same-thread and cross-thread. This issue affects all current processors that support TSX, but do not have ARCH_CAP_TAA_NO (bit 8) set in MSR_IA32_ARCH_CAPABILITIES."
The new kernels workaround the TAA flaw by either disabling Transactional Synchronization Extensions (TSX) or by clearing CPU buffers using VERW or L1D_FLUSH on all context-switches between kernel-mode and user-space. That's a costly operation.
Clawing Some Of That Performance Back[edit]
As we point out in our article "HOWTO make Linux run blazing fast (again) on Intel CPUs": It is possible to turn all the Linux kernel's security measures for Intel CPU's many security-holes off with the kernel parameter mitigations=off
TSX Async Abort (TAA) specifically can be turned on or off or set to "auto" with a new tsx= kernel option which takes the arguments on|off|auto
Using mitigations=off is not "safe" and you should not add this kernel parameter to your workplace's high-value production servers. The sky will not fall down if you add it to the kernel command line on a home computer which is used for causal web browsing and gaming and non-mission-critical applications like that.
The performance lost by updating the CPU firmware can not be clawed back by adding a kernel parameter. That performance-penalty is in the binary firmware blob running on the CPU itself. It is, in theory, possible to keep using old firmware by not updating packages like microcode_ctl or by replacing the contents of /lib/firmware/intel-ucode/ with a file like Intel-ucode-june20.tar.bz2 which contains a collection of Intel CPU firmware from June 2019. We do not recommend that anyone do this for any reason as it is unclear what Intel actually means by "unpredictable behavior" due to the CPU design flaw in Skylake and newer CPU architectures.
Is Intel Bankrupt And Finished?[edit]
The list of flaws in Intel CPUs has become rather long. Whole books can be and probably are being written about all the security holes and problems with their chips. Intel's problems have not resulted in any kind of financial difficulties for the chip giant - far from it: They are selling CPUs hand over fist.
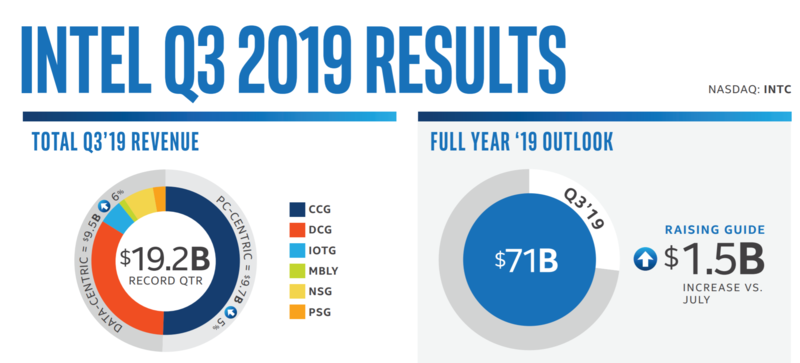
Intel's quarterly results Q3 2019
Both Intel and AMD posted record profits Q3 2019. Last quarter was, in fact, the best quarter in Intel's history. "CPU shortages" and buggy products riddled with security holes is clearly very profitable.
Writing about free software is not very profitable. We therefore do not have a single Intel CPU which is affected by the conditional jump design flaw and we can not afford to buy one. There will therefore be no in-depth testing or benchmarks of such CPUs, so sorry.
published 2019-11-16 - last edited 2019-11-17


Enable comment auto-refresher