Bash Guide for Beginners Chapter 6. The GNU awk programming language
In this chapter we will discuss:
- What is gawk?
- Using gawk commands on the command line
- How to format text with gawk
- How gawk uses regular expressions
- Gawk in scripts
- Gawk and variables
 |
TIP: To make it more fun
As with sed, entire books have been written about various versions of awk. This introduction is far from complete and is only intended for understanding examples in the following chapters. For more information, best start with the documentation that comes with GNU awk: "GAWK: Effective AWK Programming: A User's Guide for GNU Awk". |
Getting started with gawk[edit]
What is gawk?[edit]
Gawk is the GNU version of the commonly available UNIX awk program, another popular stream editor. Since the awk program is often just a link to gawk, we will refer to it as awk.
The basic function of awk is to search files for lines or other text units containing one or more patterns. When a line matches one of the patterns, special actions are performed on that line.
Programs in awk are different from programs in most other languages, because awk programs are "data-driven": you describe the data you want to work with and then what to do when you find it. Most other languages are "procedural." You have to describe, in great detail, every step the program is to take. When working with procedural languages, it is usually much harder to clearly describe the data your program will process. For this reason, awk programs are often refreshingly easy to read and write.
|
TIP: What does it really mean?
Back in the 1970s, three programmers got together to create this language. Their names were Aho, Kernighan and Weinberger. They took the first character of each of their names and put them together. So the name of the language might just as well have been "wak". |
Gawk commands[edit]
When you run awk, you specify an awk program that tells awk what to do. The program consists of a series of rules. (It may also contain function definitions, loops, conditions and other programming constructs, advanced features that we will ignore for now.) Each rule specifies one pattern to search for and one action to perform upon finding the pattern.
There are several ways to run awk. If the program is short, it is easiest to run it on the command line:
awk PROGRAM inputfile(s)
If multiple changes have to be made, possibly regularly and on multiple files, it is easier to put the awk commands in a script. This is read like this:
awk -f PROGRAM-FILE inputfile(s)
The print program[edit]
Printing selected fields[edit]
The print command in awk outputs selected data from the input file.
When awk reads a line of a file, it divides the line in fields based on the specified input field separator, FS, which is an awk variable (see Chapter 6. The GNU awk programming language, The output separators). This variable is predefined to be one or more spaces or tabs.
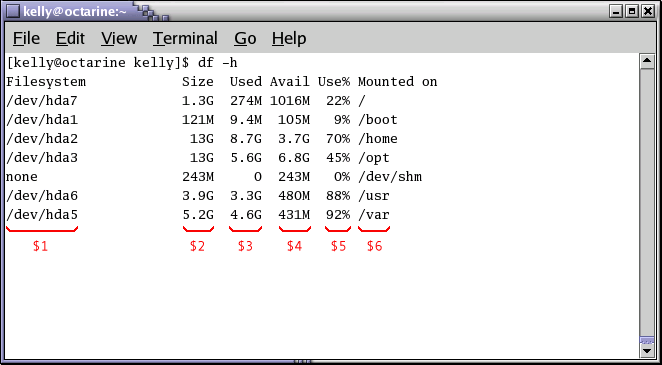
The variables $1, $2, $3, ..., $N hold the values of the first, second, third until the last field of an input line. The variable $0 (zero) holds the value of the entire line. This is depicted in the image below, where we see six colums in the output of the df command:
Figure 6-1. Fields in awk
In the output of ls -l, there are 9 columns. The print statement uses these fields as follows:
160orig 121script.sed 120temp_file 126test 120twolines 441txt2html.sh
kelly@octarine ~/test>
This command printed the fifth column of a long file listing, which contains the file size, and the last column, the name of the file. This output is not very readable unless you use the official way of referring to columns, which is to separate the ones that you want to print with a comma. In that case, the default output separater character, usually a space, will be put in between each output field.
 |
Note: Local configuration
Note that the configuration of the output of the ls -l command might be different on your system. Display of time and date is dependent on your locale setting. |
Formatting fields[edit]
Without formatting, using only the output separator, the output looks rather poor. Inserting a couple of tabs and a string to indicate what output this is will make it look a lot better:
awk '{ print "Size is " $5 " bytes for " $9 }'
Size is 160 bytes for orig Size is 121 bytes for script.sed Size is 120 bytes for temp_file Size is 126 bytes for test Size is 120 bytes for twolines Size is 441 bytes for txt2html.shkelly@octarine ~/test>
Note the use of the backslash, which makes long input continue on the next line without the shell interpreting this as a separate command. While your command line input can be of virtually unlimited length, your monitor is not, and printed paper certainly isn't. Using the backslash also allows for copying and pasting of the above lines into a terminal window.
The -h option to ls is used for supplying humanly readable size formats for bigger files. The output of a long listing displaying the total amount of blocks in the directory is given when a directory is the argument. This line is useless to us, so we add an asterisk. We also add the -d option for the same reason, in case asterisk expands to a directory.
The backslash in this example marks the continuation of a line. See Variables.
You can take out any number of columns and even reverse the order. In the example below this is demonstrated for showing the most critical partitions:
kelly@octarine ~> df -h | sort -rnk 5 | head -3 | \
Partition /var : 86% full! Partition /usr : 85% full! Partition /home : 70% full!kelly@octarine ~>
The table below gives an overview of special formatting characters:
| Sequence | Meaning |
|---|---|
| \a | Bell character |
| \n | Newline character |
| \t | Tab |
Quotes, dollar signs and other meta-characters should be escaped with a backslash.
The print command and regular expressions[edit]
A regular expression can be used as a pattern by enclosing it in slashes. The regular expression is then tested against the entire text of each record. The syntax is as follows:
awk 'EXPRESSION { PROGRAM }' file(s)
The following example displays only local disk device information, networked file systems are not shown:
/ : 46% /boot : 10% /opt : 84% /usr : 97% /var : 73% /.vol1 : 8%kelly is in ~>
Slashes need to be escaped, because they have a special meaning to the awk program.
Below another example where we search the /etc directory for files ending in ".conf" and starting with either "a" or "x", using extended regular expressions:
amd.conf antivir.conf xcdroast.conf xinetd.confkelly is in /etc>
Slashes need to be escaped, because they have a special meaning to the awk program.
Below another example where we search the /etc directory for files ending in ".conf" and starting with either "a" or "x", using extended regular expressions:
amd.conf antivir.conf xcdroast.conf xinetd.confkelly is in /etc>
This example illustrates the special meaning of the dot in regular expressions: the first one indicates that we want to search for any character after the first search string, the second is escaped because it is part of a string to find (the end of the file name).
Special patterns[edit]
In order to precede output with comments, use the BEGIN statement:
awk 'BEGIN { print "Files found:\n" } /\<[a|x].*\.conf$/ { print $9 } '
Files found: amd.conf antivir.conf xcdroast.conf xinetd.conf
kelly is in /etc>
The END statement can be added for inserting text after the entire input is processed:
kelly is in /etc> ls -l | \
awk '/\<[a|x].*\.conf$/ { print $9 } END { print \
amd.conf antivir.conf xcdroast.conf xinetd.conf Can I do anything else for you, mistress?kelly is in /etc>
Gawk scripts[edit]
As commands tend to get a little longer, you might want to put them in a script, so they are reusable. An awk script contains awk statements defining patterns and actions.
As an illustration, we will build a report that displays our most loaded partitions. See Formatting fields.
BEGIN { print "*** WARNING WARNING WARNING ***" }
/\<[8|9][0-9]%/ { print "Partition " $6 "\t: " $5 " full!" }
END { print "*** Give money for new disks URGENTLY! ***" }
kelly is in ~> df -h | awk -f diskrep.awk
*** WARNING WARNING WARNING ***
Partition /usr : 97% full!
*** Give money for new disks URGENTLY! ***
kelly is in ~>awk first prints a begin message, then formats all the lines that contain an eight or a nine at the beginning of a word, followed by one other number and a percentage sign. An end message is added.
|
TIP: Syntax highlighting
Awk is a programming language. Its syntax is recognized by most editors that can do syntax highlighting for other languages, such as C, Bash, HTML, etc. |
Gawk variables[edit]
As awk is processing the input file, it uses several variables. Some are editable, some are read-only.
The input field separator[edit]
The field separator, which is either a single character or a regular expression, controls the way awk splits up an input record into fields. The input record is scanned for character sequences that match the separator definition; the fields themselves are the text between the matches.
The field separator is represented by the built-in variable FS. Note that this is something different from the IFS variable used by POSIX-compliant shells.
The value of the field separator variable can be changed in the awk program with the assignment operator =. Often the right time to do this is at the beginning of execution before any input has been processed, so that the very first record is read with the proper separator. To do this, use the special BEGIN pattern.
In the example below, we build a command that displays all the users on your system with a description:
--output omitted-- kelly Kelly Smith franky Franky B. eddy Eddy White willy William Black cathy Catherine the Great sandy Sandy Li Wongkelly is in ~>
In an awk script, it would look like this:
BEGIN { FS=":" }
{ print $1 "\t" $5 }
kelly is in ~> awk -f printnames.awk /etc/passwd--output omitted--
Choose input field separators carefully to prevent problems. An example to illustrate this: say you get input in the form of lines that look like this:
"Sandy L. Wong, 64 Zoo St., Antwerp, 2000X"
You write a command line or a script, which prints out the name of the person in that record:
awk 'BEGIN { FS="," } { print $1, $2, $3 }' inputfile
But a person might have a PhD, and it might be written like this:
"Sandy L. Wong, PhD, 64 Zoo St., Antwerp, 2000X"
Your awk will give the wrong output for this line. If needed, use an extra awk or sed to uniform data input formats.
The default input field separator is one or more whitespaces or tabs.
The output separators[edit]
The output field separator[edit]
Fields are normally separated by spaces in the output. This becomes apparent when you use the correct syntax for the print command, where arguments are separated by commas:
record1 data1 record2 data2kelly@octarine ~/test> awk '{ print $1 $2}' test
record1data1 record2data2kelly@octarine ~/test> awk '{ print $1, $2}' test
record1 data1 record2 data2kelly@octarine ~/test>
If you don't put in the commas, print will treat the items to output as one argument, thus omitting the use of the default output separator, OFS.
Any character string may be used as the output field separator by setting this built-in variable.
The output record separator[edit]
The output from an entire print statement is called an output record. Each print command results in one output record, and then outputs a string called the output record separator, ORS. The default value for this variable is "\n", a newline character. Thus, each print statement generates a separate line.
To change the way output fields and records are separated, assign new values to OFS and ORS:
{ print $1,$2}' test
record1;data1 --> record2;data2 -->kelly@octarine ~/test>
If the value of ORS does not contain a newline, the program's output is run together on a single line.
The number of records[edit]
The built-in NR holds the number of records that are processed. It is incremented after reading a new input line. You can use it at the end to count the total number of records, or in each output record:
BEGIN { OFS="-" ; ORS="\n--> done\n" }
{ print "Record number " NR ":\t" $1,$2 }
END { print "Number of records processed: " NR }
kelly@octarine ~/test> awk -f processed.awk testRecord number 1: record1-data1 --> done Record number 2: record2-data2 --> done Number of records processed: 2 --> donekelly@octarine ~/test>
User defined variables[edit]
Apart from the built-in variables, you can define your own. When awk encounters a reference to a variable which does not exist (which is not predefined), the variable is created and initialized to a null string. For all subsequent references, the value of the variable is whatever value was assigned last. Variables can be a string or a numeric value. Content of input fields can also be assigned to variables.
Values can be assigned directly using the = operator, or you can use the current value of the variable in combination with other operators:
kelly@octarine ~> cat revenues 20021009 20021013 consultancy BigComp 2500 20021015 20021020 training EduComp 2000 20021112 20021123 appdev SmartComp 10000 20021204 20021215 training EduComp 5000
kelly@octarine ~> cat total.awk{ total=total + $5 }
{ print "Send bill for " $5 " dollar to " $4 }
END { print "---------------------------------\nTotal revenue: " total }
kelly@octarine ~> awk -f total.awk testSend bill for 2500 dollar to BigComp Send bill for 2000 dollar to EduComp Send bill for 10000 dollar to SmartComp Send bill for 5000 dollar to EduComp --------------------------------- Total revenue: 19500kelly@octarine ~>
C-like shorthands like VAR+= value are also accepted.
More examples[edit]
The example from "Writing output files" becomes much easier when we use an awk script:
BEGIN { print "<html>\n<head><title>Awk-generated HTML</title></head>\n<body bgcolor=\"#ffffff\">\n<pre>" }
{ print $0 }
END { print "</pre>\n</body>\n</html>" }
And the command to execute is also much more straightforward when using awk instead of sed:
 |
Awk examples on your system
We refer again to the directory containing the initscripts on your system. Enter a command similar to the following to see more practical examples of the widely spread usage of the awk command: grep awk /etc/init.d/* |
The printf program[edit]
For more precise control over the output format than what is normally provided by print, use printf. The printf command can be used to specify the field width to use for each item, as well as various formatting choices for numbers (such as what output base to use, whether to print an exponent, whether to print a sign, and how many digits to print after the decimal point). This is done by supplying a string, called the format string, that controls how and where to print the other arguments.
The syntax is the same as for the C-language printf statement; see your C introduction guide. The gawk info pages contain full explanations.
Summary[edit]
The gawk utility interprets a special-purpose programming language, handling simple data-reformatting jobs with just a few lines of code. It is the free version of the general UNIX awk command.
This tools reads lines of input data and can easily recognize columned output. The print program is the most common for filtering and formatting defined fields.
On-the-fly variable declaration is straightforward and allows for simple calculation of sums, statistics and other operations on the processed input stream. Variables and commands can be put in awk scripts for background processing.
Other things you should know about awk:
- The language remains well-known on UNIX and alikes, but for executing similar tasks, Perl is now more commonly used. However, awk has a much steeper learning curve (meaning that you learn a lot in a very short time). In other words, Perl is more difficult to learn.
- Both Perl and awk share the reputation of being incomprehensible, even to the actual authors of the programs that use these languages. So document your code!
Exercises[edit]
1. For the first exercise, your input is lines in the following form:
Username:Firstname:Lastname:Telephone number
Make an awk script that will convert such a line to an LDAP record in this format:
dn: uid=Username, dc=example, dc=com cn: Firstname Lastname sn: Lastname telephoneNumber: Telephone number
Create a file containing a couple of test records and check.
2. Create a Bash script using awk and standard UNIX commands that will show the top three users of disk space in the /home file system (if you don't have the directory holding the homes on a separate partition, make the script for the / partition; this is present on every UNIX system). First, execute the commands from the command line. Then put them in a script. The script should create sensible output (sensible as in readable by the boss). If everything proves to work, have the script email its results to you (use for instance mail -s Disk space usage <you@your_comp> < result).
If the quota daemon is running, use that information; if not, use find.
3. Create XML-style output from a Tab-separated list in the following form:
Meaning very long line with a lot of description meaning another long line othermeaning more longline testmeaning looooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooong line, but i mean really looooooooooooooooooooooooooooooooooooooooooooooooooong.
The output should read:
<row> <entry>Meaning</entry> <entry> very long line </entry> </row> <row> <entry>meaning</entry> <entry> long line </entry> </row> <row> <entryothermeaning</entry> <entry> more longline </entry> </row> <row> <entrytestmeaning</entry> <entry> looooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooong line, but i mean really looooooooooooooooooooooooooooooooooooooooooooooooooong. </entry> </row>
Additionally, if you know anything about XML, write a BEGIN and END script to complete the table. Or do it in HTML.
